If anyone here is working on AI video, I can think of a few ways it might be useful. I have suggested before, the idea of using CGI or even 3D animation to produce the "set up" portion of a scene, with the sinking portion subsequently filmed using a real pit and live performers. As I conceive it there would be no quicksand or recognizable people in the synthetic part, thus avaoiding all issues of copyright.
Consider this, for example: People here, mostly Duncan Edwards, have talked for years about a scene with a bus full of cheerleaders that breaks down or crashes in a swampy area, followed by two-dozen stereotypical cheerleaders all out for themselves in the swamp. Imagine a scene that opens with a yellow bus taking a wrong turn on a dirt road, crashing into a pond or ditch. Then the doors open and the cheerleaders flood out, shown from far enough away that faces are not scene well enough to notice they are synthetic. That is the end of the set-up. From this point on we have a series of scenes. In each, there are one or two cheerleaders crashng through the forest, blundering into a bog, and sinking.
It might even be feasible for the sinking scenes to be filmed in different places by different producers. For that there should be, in my view, some collaboration so as to agree on details such as the colors of the uniforms.
And if the above could actually be done, then the whole idea could be repeated with the bus being a travel but for an all-female rock group, or a dozen other things.
AI video?
-
Fred588
- Producer
- Posts: 17832
- Joined: Sat Apr 11, 2009 3:37 pm
- Location: Central Arkansas (At Studio 588)
- Contact:
AI video?
Studio 588 currently offers more than 2200 different HD and QD quicksand videos and has supported production of well over 2400 video scenes and other projects by 20 different producers. Info may be found at:
http://studio588qs.com
http://quicksandland.com
http://psychicworldjungleland.com
http://studio588qs.com
http://quicksandland.com
http://psychicworldjungleland.com
-
Viridian

- Posts: 1673
- Joined: Wed Apr 15, 2009 4:03 am
Re: AI video?
I've done this as a concept already:
viewtopic.php?f=30&t=29077#p170885
We can also face-match with models to improve consistency.
Currently the main limitation with AI video is that it's not very good at constructing a specific scene - it might give you something that _resembles_ the scene, but never what you want. It comes down to someone with good AI _image_ generation knowledge to craft the right source images for the AI to interpret.
Secondly, it struggles with how objects interact. It's hard to consistently coerce the AI to make a subject move in the right direction, hold something, etc. It goes "fuzzy" - it might blend people walking to their legs and faces turning in the wrong direction like possessed witches. It's actually quite creepy working with unsuccessful results with AI, as it constantly rebounds to things that it expects the prompt words to see (e.g. it generates a lot of identical cheerleaders doing poses, even on a bus).
I get around that by using basic film techniques to focus more on close ups and cuts to give the impression of a sequence of events, but I try to avoid using scenes that involve complex interaction. However, I do believe that we're at - or very near - the stage where we can use AI to set up scenes that producers can integrate into their video concepts.
viewtopic.php?f=30&t=29077#p170885
We can also face-match with models to improve consistency.
Currently the main limitation with AI video is that it's not very good at constructing a specific scene - it might give you something that _resembles_ the scene, but never what you want. It comes down to someone with good AI _image_ generation knowledge to craft the right source images for the AI to interpret.
Secondly, it struggles with how objects interact. It's hard to consistently coerce the AI to make a subject move in the right direction, hold something, etc. It goes "fuzzy" - it might blend people walking to their legs and faces turning in the wrong direction like possessed witches. It's actually quite creepy working with unsuccessful results with AI, as it constantly rebounds to things that it expects the prompt words to see (e.g. it generates a lot of identical cheerleaders doing poses, even on a bus).
I get around that by using basic film techniques to focus more on close ups and cuts to give the impression of a sequence of events, but I try to avoid using scenes that involve complex interaction. However, I do believe that we're at - or very near - the stage where we can use AI to set up scenes that producers can integrate into their video concepts.
Last edited by Viridian on Sat Mar 08, 2025 6:54 pm, edited 1 time in total.
Viridian @ deviantART: http://viridianqs.deviantart.com/
-
Viridian
- Posts: 1673
- Joined: Wed Apr 15, 2009 4:03 am
Re: AI video?
I had a go at creating your setup. I might consider myself to be in the higher tier of what AI creators are making on a technical level, so this probably reflects what we can currently do.
AI can _animate_ a scene - it doesn't _create_ the scene well. If you give it an image of a bus with a smoking hood, it will animate the effects very nicely. But if you give it an image of a normal bus and tell it to make it smoke, it has an existential crisis and just pours smoke everywhere in the scene. Or it literally does nothing.
In other words, the AI can't be creative. It can't anticipate what it is next. You can't make it crash a bus into a tree, for example, because it doesn't have a model that can render those physics. Hence it suits my style of film-making - using cuts and cues to visually tell the story (more efficiently), which also cuts down on effort and production cost.
Ironically, you mentioned that you might favour long shots to reduce the "synthetic" look of AI. AI is actually terrible at longer shots with less detail. It works very well in close ups, whereas long shots with fewer pixels gives it less to generate, so faces turn into melted dolls. Plus it tends to clone dozens of the same faces and outfits, so it turns into a literal clown show if you want dozens of cheerleaders getting off a bus.
As an aside, I absolutely _hate_ working with the cheerleader trope with AI. Virtually every image I generated with cheerleaders would throw up an entire team doing poses. The AI models associate teams and poses too strongly with cheerleaders.
AI can _animate_ a scene - it doesn't _create_ the scene well. If you give it an image of a bus with a smoking hood, it will animate the effects very nicely. But if you give it an image of a normal bus and tell it to make it smoke, it has an existential crisis and just pours smoke everywhere in the scene. Or it literally does nothing.
In other words, the AI can't be creative. It can't anticipate what it is next. You can't make it crash a bus into a tree, for example, because it doesn't have a model that can render those physics. Hence it suits my style of film-making - using cuts and cues to visually tell the story (more efficiently), which also cuts down on effort and production cost.
Ironically, you mentioned that you might favour long shots to reduce the "synthetic" look of AI. AI is actually terrible at longer shots with less detail. It works very well in close ups, whereas long shots with fewer pixels gives it less to generate, so faces turn into melted dolls. Plus it tends to clone dozens of the same faces and outfits, so it turns into a literal clown show if you want dozens of cheerleaders getting off a bus.
As an aside, I absolutely _hate_ working with the cheerleader trope with AI. Virtually every image I generated with cheerleaders would throw up an entire team doing poses. The AI models associate teams and poses too strongly with cheerleaders.
You do not have the required permissions to view the files attached to this post.
Viridian @ deviantART: http://viridianqs.deviantart.com/
-
sixgunzloaded
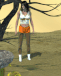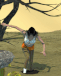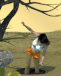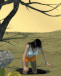
- Posts: 974
- Joined: Tue May 05, 2015 2:16 pm
Re: AI video?
Viridian wrote:As an aside, I absolutely _hate_ working with the cheerleader trope with AI. Virtually every image I generated with cheerleaders would throw up an entire team doing poses. The AI models associate teams and poses too strongly with cheerleaders.
What about just eliminating the word "cheerleader" entirely from the prompts? Maybe instead, try something like just describing their uniforms in detail to match what cheerleaders typically wear and then telling the AI to apply it to all the girls in the scene?
Possibly eliminate the words "team" and "pose" as well?
How long did Tarzan watch before deciding to save Jill..?
-
Viridian
- Posts: 1673
- Joined: Wed Apr 15, 2009 4:03 am
Re: AI video?
sixgunzloaded wrote:What about just eliminating the word "cheerleader" entirely from the prompts? Maybe instead, try something like just describing their uniforms in detail to match what cheerleaders typically wear and then telling the AI to apply it to all the girls in the scene?
Possibly eliminate the words "team" and "pose" as well?
There's definitely room for experimentation and work-arounds. Cheerleader uniforms are quite distinct, depending on what you are going for. You could plug in items like skirts and long-sleeve shirts as alternatives and avoid the word association, but then the AI will struggle to put together what you might envision the cheerleader to look like.
"Team" and "pose" is not in the prompt. The AI strongly associates those with cheerleaders, cheer or cheerleader uniforms. You also can't really control exactly what the uniform looks like. That's why my bus video has all different kinds. I rely on suspense of disbelief to pass them off as variations of a blue team rather than try to design a uniform that I could replicate.
Viridian @ deviantART: http://viridianqs.deviantart.com/
-
Duncan Edwards

- Posts: 4211
- Joined: Sat Apr 11, 2009 11:41 am
Re: AI video?
Here's a "rough draft" of Paris as a Messyfun University Cheerleader. The most recent iteration is much better. If one were intending to copy Pete Boggs original work, it ain't bad. It's no more difficult to create cheerleaders that are remarkably similar to how their MPV contemporaries might portray the pen and ink originals. 
Just for comparison with an original -
Just for comparison with an original -
You do not have the required permissions to view the files attached to this post.
It's a dirty job but I got to do it for 27 years. Thank you.
-
Chimerix

- Posts: 882
- Joined: Wed Apr 15, 2009 3:44 am
- Contact:
Re: AI video?
Viridian wrote:I had a go at creating your setup. I might consider myself to be in the higher tier of what AI creators are making on a technical level, so this probably reflects what we can currently do.
That looks pretty great! I love that the squad is standing there, looking around, in "default pose #3", fists on hips, so accustomed to looking hot and posing that it's become their daily norm, even offstage.
And teh three walking through the woods holding hands? I love it! Love seeing women holding hands. Especially when I've reason to believe that, soon, there will be quicksand involved!
The difference between theory and reality is that, in theory, there is no difference between theory and reality.
-
mjw
- Posts: 22
- Joined: Thu Dec 07, 2023 6:24 am
Re: AI video?
I've been playing around a bit with the Flux AI Video generator (and spent all my one-off credits doing so).
It's really hard to get it to do just what you want. The best I've found is to get a starting image and an ending image and give it a prompt on how to get from the start to the end. It seems like the only way to get it not turn into muddy water rather than mud or QS is to have an ending image. Also keeping it simple (a single person) is best.
For a fully AI video the trouble is getting the AI to generate a still image before and after of the same bit of mud or background. The best I've managed is to keep tweaking the prompt to get a good starting image, then describe what should happen in the video and hope for the best. Another approach might be to start off with ChatGPT which is quite good at making a series of images with the same AI generated character, and use Flux AI to fill in the part inbetween.
No doubt AI video will improve but by far the best results have been from using a starting and ending photo that we've taken.
It's really hard to get it to do just what you want. The best I've found is to get a starting image and an ending image and give it a prompt on how to get from the start to the end. It seems like the only way to get it not turn into muddy water rather than mud or QS is to have an ending image. Also keeping it simple (a single person) is best.
For a fully AI video the trouble is getting the AI to generate a still image before and after of the same bit of mud or background. The best I've managed is to keep tweaking the prompt to get a good starting image, then describe what should happen in the video and hope for the best. Another approach might be to start off with ChatGPT which is quite good at making a series of images with the same AI generated character, and use Flux AI to fill in the part inbetween.
No doubt AI video will improve but by far the best results have been from using a starting and ending photo that we've taken.
Who is online
Users browsing this forum: No registered users and 1 guest